Vision for Zoe¶
Zoe focus is data analytics. This focus helps defining a clear set of objectives and priorities for the project and avoid the risk of competing directly with generic infrastructure managers like Kubernetes or Swarm. Zoe instead sits on top of these “cloud managers” to provide a simpler interface to end users who have no interest in the intricacies of container infrastructures.
Data analytic applications do not work in isolation. They need data, that may be stored or streamed, and they generate logs, that may have to be analyzed for debugging or stored for auditing. Data layers, in turn, need health monitoring. All these tools, frameworks, distributed filesystems, object stores, form a galaxy that revolves around analytic applications. For simplicity we will call these “support applications”.
To offer an integrated, modern solution to data analysis Zoe must support both analytic and support applications, even if they have very different users and requirements.
The users of Zoe¶
- users: the real end-users, who submit non-interactive analytic jobs or use interactive applications
- admins: systems administrators who maintain Zoe, the data layers, monitoring and logging for the infrastructure and the apps being run
Deviation from the current ZApp terminology¶
In the current Zoe implementation ZApps are self-contained descriptions of a set of cooperating processes. They get submitted once, to request the start-up of an execution. This fits well the model of a single spark job or of a throw-away jupyter notebook.
ZApps are at the top level, they are the user-visible entity. The ZApp building blocks, analytic engines or support tools, are called frameworks. A framework, by itself, cannot be run. It lacks configuration or a user-provided binary to execute, for example. Each framework is composed of one or more processes, that come with some metadata of the needed configuration and a container image.
A few examples:
- A Jupyter notebook, by itself, is a framework in Zoe terminology. It lacks configuration that tells it which kernels to enable or on which port to listen to. It is a framework composed by just one process.
- A Spark cluster is another framework. By itself it does nothing. It can be connected to a notebook, or it can be given a jar file and some data to process.
- A “Jupyter with R listening on port 8080” ZApp is a Jupyter framework that has been configured with certain options and made runnable
To create a ZApp you need to put together one or more frameworks and add some configuration (framework-dependent) that tells them how to behave.
A ZApp shop could contain both frameworks (that the user must combine together) and full-featured ZApps.
Nothing prevents certain ZApp attributes to be “templated”, like resource requests or elastic process counts, for example.
Kinds of applications¶
See Classification.
Architecture¶
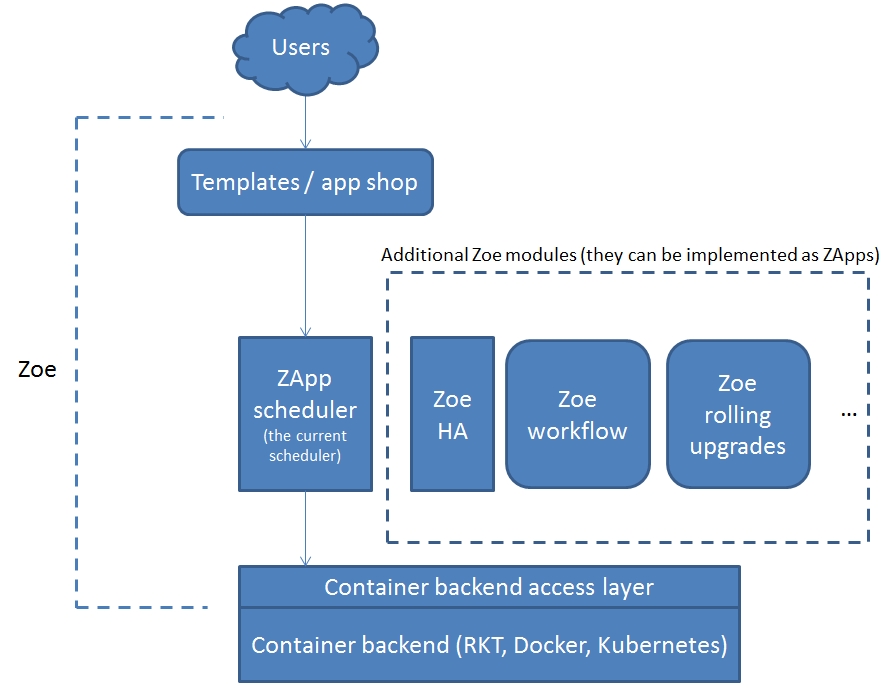
This architecture extends the current one by adding a number of pluggable modules that implement additional (and optional) features. The additional modules, in principle, are created as more Zoe frameworks, that will be instantiated in ZApps and run through the scheduler together with all the other ZApps.
The core of Zoe remains very simple to understand, while opening the door to more capabilities. The additional modules will have the ability of communicating with the backend, submit, modify and terminate executions via the scheduler and report information back to the user. Their actions will be driven by additional fields written in the ZApps descriptions.
In the figure there are three examples of such modules:
- Zoe-HA: monitors and performs tasks related to high availability, both for Zoe components and for running user executions. This modules could take care of maintaining a certain replication factor, or making sure a certain service is restarted in case of failures, updating a load balancer or a DNS entry
- Zoe rolling upgrades: performs rolling upgrades of long-running ZApps
- Workflows (see the section below)
Other examples could be:
- Zoe-storage: for managing volumes and associated constraints
The modules should try to re-use as much as possible the functionality already available in the backends. A simple Zoe installation could run on a single Docker engine available locally and provide a reduced set of features, while a full-fledged install could run on top of Kubernetes and provide all the large-scale deployment features that such platform already implements.
Workflows¶
A few examples of workflows:
- run a job every hour (triggered by time)
- run a set of jobs in series or in parallel (triggered by the state of other jobs)
- run a job whenever the size of a file/directory/bucket on a certain data layer reaches 5GB (more complex triggers)
- combinations of all the above
A complete workflow system for data analytic is very complex. There is a lot of theory on this topic and zoe-workflow is a project of the same size as Zoe itself. An example of a full-featured workflow system for Hadoop is http://oozie.apache.org/